Aggregation in MongoDB
Aggregation is the process of selecting data from a collection in MongoDB. It processes multiple documents and returns computed results.
Use aggregation to group values from multiple documents, or perform operations on the grouped data to return a single result.
Aggregation operations can be performed in two ways:
- Using Aggregation Pipeline.
- Using single purpose aggregation methods: db.collection.estimatedDocumentCount(),db.collection.count() and db.collection.distinct().
Aggregation Pipelines
The aggregation pipeline is an array of one or more stages passed in the db.aggregate() or db.collection.aggregate() method.
db.collection.aggregate([ {stage1}, {stage2}, {stage3}...])Aggregation framework processes the pipeline of stages on the collection data and gives you output in the form you needed.
Every stage receives the output of the previous stage, processes the data further, and sends it to the next stage as input data. Aggregation pipeline executes on the server can take advantage of indexes. See the list of stages here.
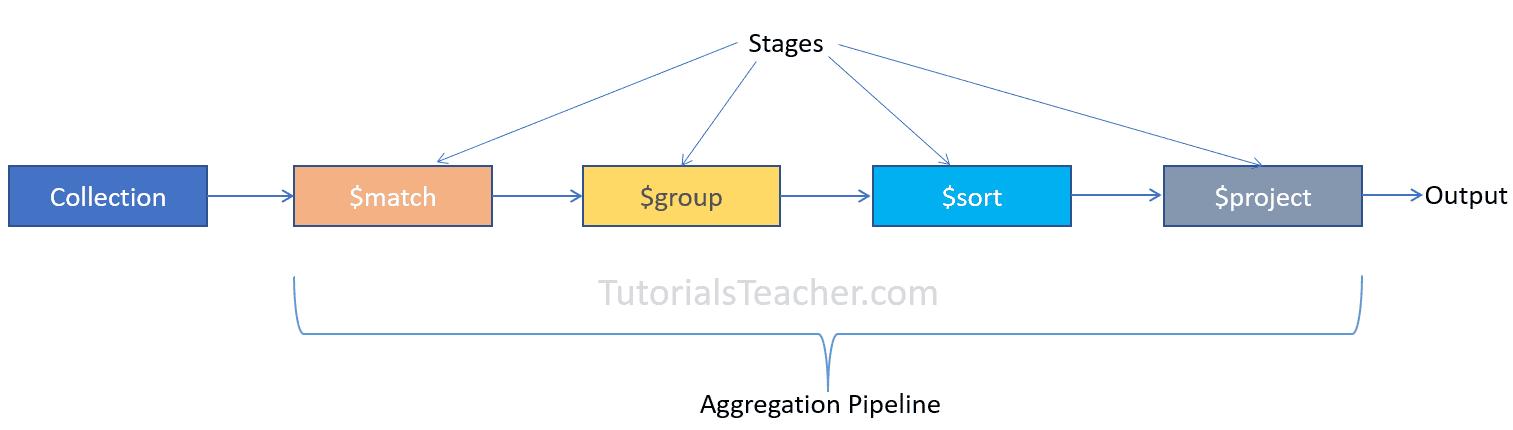
Let's see how to use different stages on the following employees collection.
db.employees.insertMany([
{
_id:1,
firstName: "John",
lastName: "King",
gender:'male',
email: "[email protected]",
salary: 5000,
department: {
"name":"HR"
}
},
{
_id:2,
firstName: "Sachin",
lastName: "T",
gender:'male',
email: "[email protected]",
salary: 8000,
department: {
"name":"Finance"
}
},
{
_id:3,
firstName: "James",
lastName: "Bond",
gender:'male',
email: "[email protected]",
salary: 7500,
department: {
"name":"Marketing"
}
},
{
_id:4,
firstName: "Rosy",
lastName: "Brown",
gender:'female',
email: "[email protected]",
salary: 5000,
department: {
"name":"HR"
}
},
{
_id:5,
firstName: "Kapil",
lastName: "D",
gender:'male',
email: "[email protected]",
salary: 4500,
department: {
"name":"Finance"
}
},
{
_id:6,
firstName: "Amitabh",
lastName: "B",
gender:'male',
email: "[email protected]",
salary: 7000,
department: {
"name":"Marketing"
}
}
])$match Stage
The $match stage is usually the first stage to select only the matching documents from a collection. It is equivalent to the Find() method. The following example demonstrates an aggregation pipeline with a single $match stage.
db.employees.aggregate([ {$match:{ gender: 'female'}} ])In the above example, the $match stage is specified as a document {$match:{ gender: 'female'}} in an array. It will return all documents where gender:'female' filed.
[
{
_id: 4,
firstName: 'Rosy',
lastName: 'Brown',
gender: 'female',
email: '[email protected]',
salary: 5000,
department: { name: 'HR' }
}
]The $match stage in the aggregate() method gives the same output as the find() method. The db.persons.find({ gender: 'female' }) would return the same data as above.
$group Stage
Use the $group stage to group the input documents by the specified _id expression and returns a single document containing the accumulated values for each distinct group. Consider the following example.
db.employees.aggregate([
{ $group:{ _id:'$department.name'} }
])[ { _id: 'Marketing' }, { _id: 'HR' }, { _id: 'Finance' } ]In the above example, only the $group stage is specified in the pipeline array. The $group uses _id field to calculate the accumulated values for all the input documents as a whole. The expression { _id:'$department.name'} creates the distinct group on the field $department.name. Since we don't calculate any accumulated values, it returns the distinct values of $department.name, as shown below.
Now, let's calculate the accumulated values for each group. The following calculates the number of employees in each department.
db.employees.aggregate([
{ $group:{ _id:'$department.name', totalEmployees: { $sum:1 } }
}])[
{ _id: 'Marketing', totalEmployees: 2 },
{ _id: 'HR', totalEmployees: 2 },
{ _id: 'Finance', totalEmployees: 2 }
]In the above example, we create distinct groups using _id:'$department.name' expression. In the second expression totalEmployees: { $sum:1 }, the totalEmployees is a field that will be included in the output, and { $sum:1 } is an accumulator expression where $sum is an Accumulator Operator that returns a sum of numerical values. Here, { $sum:1 } adds 1 for each document that falls under the same group.
The following aggregation pipeline contains two stages.
db.employees.aggregate([
{ $match:{ gender:'male'}},
{ $group:{ _id:'$department.name', totalEmployees: { $sum:1 } }
}])[
{ _id: 'Marketing', totalEmployees: 2 },
{ _id: 'HR', totalEmployees: 1 },
{ _id: 'Finance', totalEmployees: 2 }
]In the above example, the first stage selects all male employees and passes them as input to the second stage $group as an input. So, the output calculates the sum of all male employees.
The following calculates the sum of salaries of all male employees in the same department.
db.employees.aggregate([
{ $match:{ gender:'male'}},
{ $group:{ _id:{ deptName:'$department.name'}, totalSalaries: { $sum:'$salary'} }
}])[
{ _id: 'Finance', totalSalaries: 12500 },
{ _id: 'HR', totalSalaries: 10000 },
{ _id: 'Marketing', totalSalaries: 14500 }
]In the above example, { $match:{ gender:'male'}} returns all male employees. In the $group stage, an accumulator expression totalSalaries: { $sum:'$salary'} sums up numeric field salary and include it as totalSalaries in the output for each group.
$sort Stage
The $sort stage is used to sort the documents based on the specified field in ascending or descending order. The following sorts all male employees.
db.employees.aggregate([
{ $match:{ gender:'male'}},
{ $sort:{ firstName:1}}
])[
{
_id: 6,
firstName: 'Amitabh',
lastName: 'B',
gender: 'male',
email: '[email protected]',
salary: 7000,
department: { name: 'Marketing' }
},
{
_id: 3,
firstName: 'James',
lastName: 'Bond',
gender: 'male',
email: '[email protected]',
salary: 7500,
department: { name: 'Marketing' }
},
{
_id: 1,
firstName: 'John',
lastName: 'King',
gender: 'male',
email: '[email protected]',
salary: 5000,
department: { name: 'HR' }
},
{
_id: 5,
firstName: 'Kapil',
lastName: 'D',
gender: 'male',
email: '[email protected]',
salary: 4500,
department: { name: 'Finance' }
},
{
_id: 2,
firstName: 'Sachin',
lastName: 'T',
gender: 'male',
email: '[email protected]',
salary: 8000,
department: { name: 'Finance' }
}
]In the above example, the $match stage returns all the male employees and passes it to the next stage $sort. The { $sort:{ firstName:1}} expression sorts the input documents by the firstName field in ascending order. 1 indicates the ascending order and -1 indicates descending order.
The following pipeline contains three stages to sort the groupped documents.
db.employees.aggregate([
{ $match:{ gender:'male'}},
{ $group:{ _id:{ deptName:'$department.name'}, totalEmployees: { $sum:1} } },
{ $sort:{ deptName:1}}
])[
{ _id: { deptName: 'Finance' }, totalEmployees: 2 },
{ _id: { deptName: 'HR' }, totalEmployees: 1 },
{ _id: { deptName: 'Marketing' }, totalEmployees: 2 }
]Thus, you can use the aggregation pipeline to get the required documents from the collection.